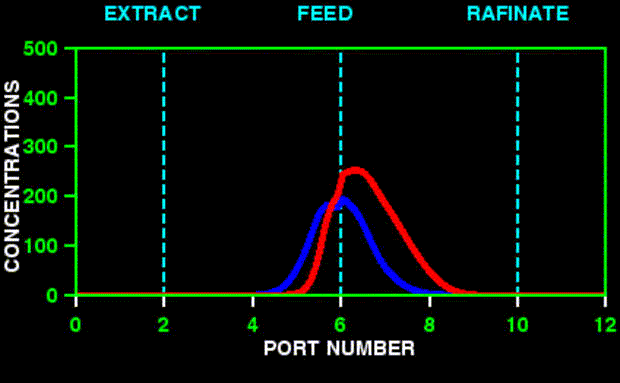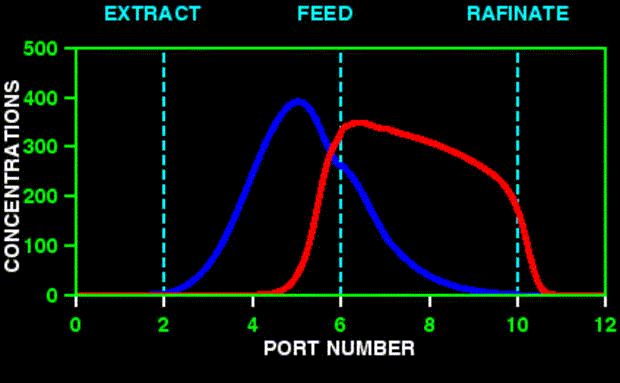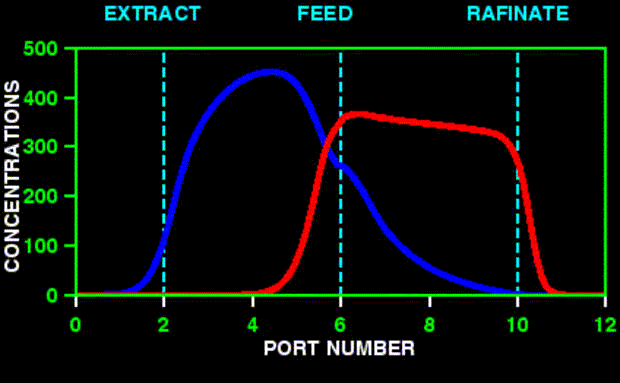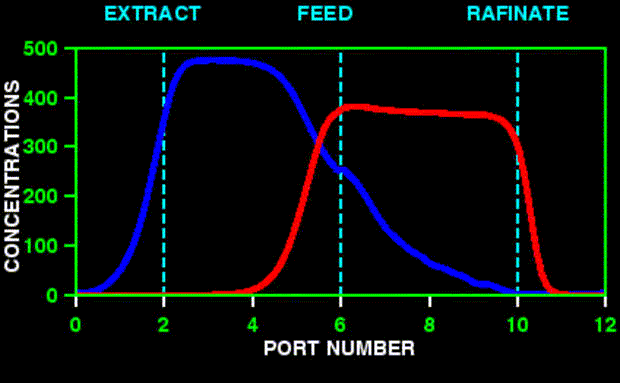
![]()
|
|
|||||||||
|
|
|
|
|
|
|
|
|
||
![]()
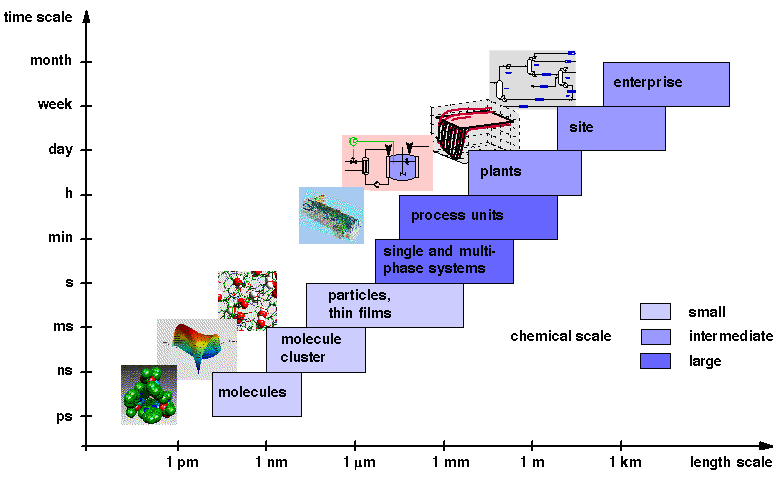
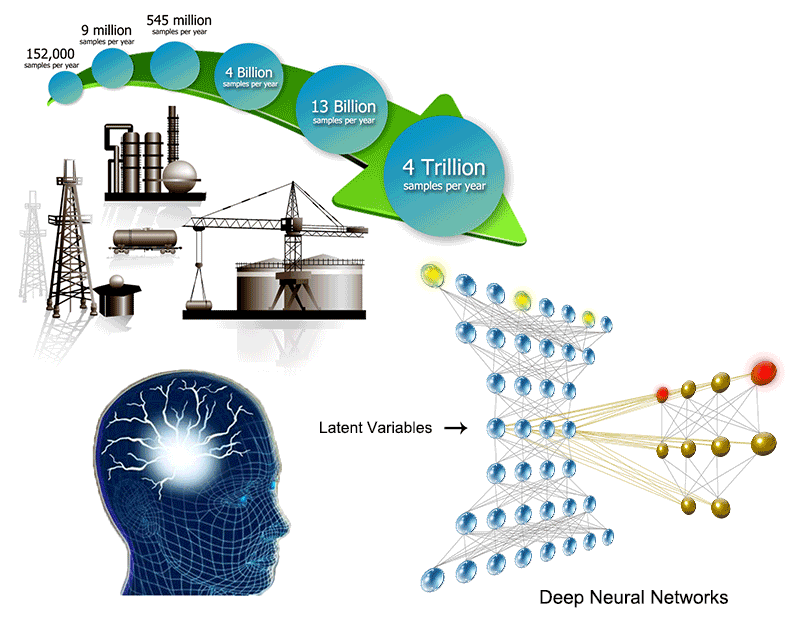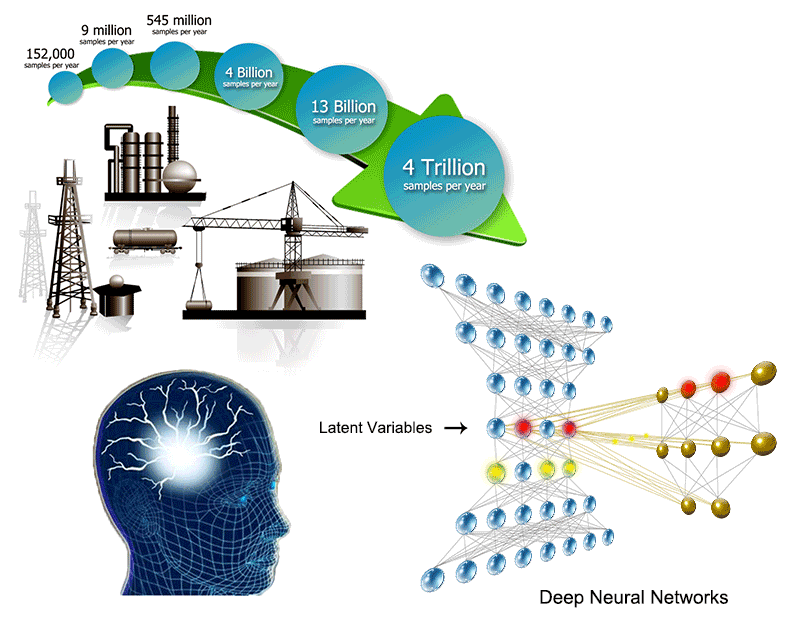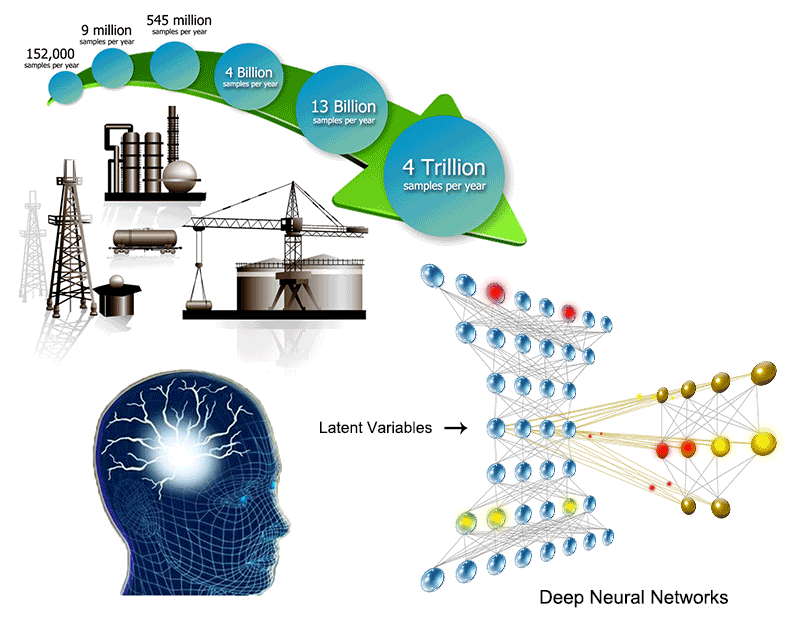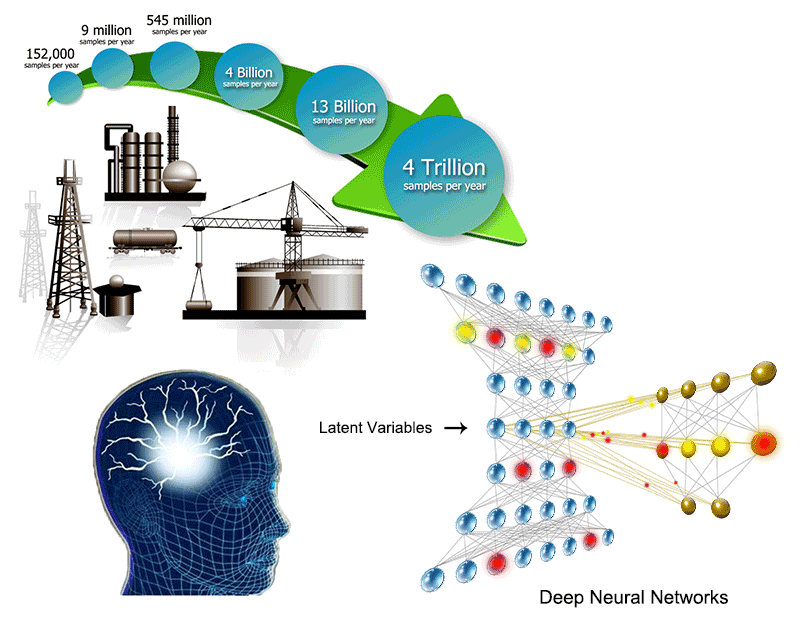
Our research focuses on the statistical analysis approach (so-called data-driven approach) to process optimal design and control. It is motivated by the need for dealing with massive amounts of process data ("Big Data") collected routinely by on-line computers in manufacturing products. The research is multidisciplinary in nature. It relies on the use of several exciting new data analysis techniques in powerful computation, numerical optimization, information statistics, data mining, machine learning algorithms, and novel sensors to handle data information. Data can be more readily analyzed and interpreted to improve the safety and efficiency of the operating process and to save energy loss. On-going research shown as below is being performed. In addition to the fundamental research, several studies on application to challenging and complex industrial process design and control problems, such as big data oriented plant-wide process analysis, assessment of plant-wide control loops, simulated moving bed separation systems, pressure swing adsorption processes, biofuel production processes and membrane separation systems, have been successfully conducted. Thank you for your interest and feel free to contact us for more information if you have further questions. Brief descriptions of the current topics are provided below.
![]()
Developing Latent Variable-Based Machining Learning (or Data Mining) Algorithms to Enhance Performance of Operating Processes (開發以潛變數為基礎的機械學習(或數據趨動)演算法,以提昇操作程序的效能)
|
|
Process complexity and high demands for enhancing
controlled processes have driven the development of new machine learning (or
data-driven) techniques. Among them, latent variable (LV) models have been
widely applied to process modeling and data analysis. These LV models are proved
to be effective because they are able to decompose the observation space into
the LV subspace and the residual subspace. The LV subspace describes process
mapping, known as a generative model, from LVs to the observed variables. On the
other hand, the residual subspace represents the space spanned by measurement
noises.
Our research work is focused on developing new LV based algorithms based on
different types of processes. The core techniques we currently working on
include piece-wise linear or nonlinear models, shallow or deep models,
deterministic or stochastic models, and probabilistic or projection-based
models. Specifically, we focus on
General Topics in Process System Engineering
 |
 |
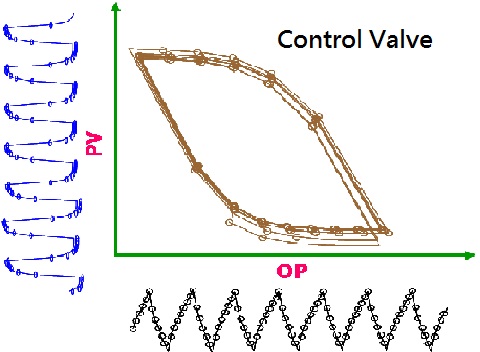
Modern operation plants are composed of several kinds of highly complex processes and integrated units. This makes them susceptible to various failures that cause an unacceptable deterioration of the performance or even lead to dangerous situations. This area of research involves the utilization and development of various data analysis methods (such as multivariable statistical method, wavelet transform, fractal encoding, neural networks and hidden Markov model) for monitoring and diagnosing the status of the current operating process. Much of this theoretical research is directly applied to the industrial cases, including the manufacturing ceramic glaze, the surface quality in stainless steel slabs, combustors, and the plasma-etching reactor. (現代化的化學工廠是整合數種不同的高複雜程序與單元所組成,因此較易於導致各式各樣的失敗製程,這將引起無可接受的製程效能降低,甚至有危險之慮。本研究領域包含運用與發展各種數據分析的方法(如多變數統計方法、小波轉換、碎形編碼、類神經網路,以及隱藏式Markov模式),用以監控與診斷目前操作程序的狀態。本研究大多直接應用於工業實例,包含釉料反應系統、鋼板表面品質的控制、 燃燒爐、與電漿蝕刻反應器等等。)
|
|
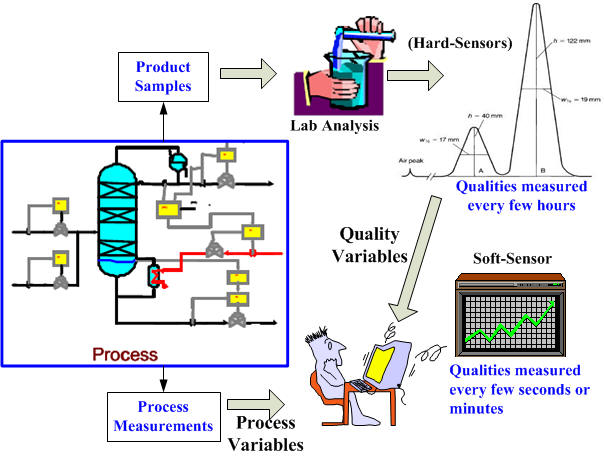
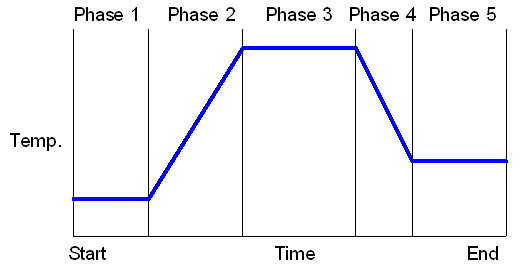
The production of products requires frequent change of operating conditions with market changes. However, product qualities, such as melt index (MI), are often analyzed off-line and infrequently. Consequently, grade changeover typically is a manual operation in many industrial plants, and it results in relatively large settling time, overshoots and off-grade materials. Developing an advanced control system to provide optimal grade changeover trajectories to reduce the amount of off-grade materials is critical. Alternatively, process data have become widely available in many chemical plants and thus data-driven soft sensors are adopted to predict product qualities that are difficult to measure online.
|
|
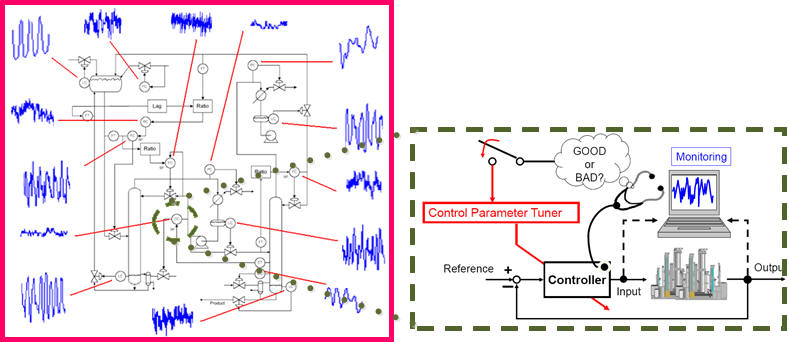
Many processes have been around for years, but some operational problems still go undiagnosed for a prolonged period of time. If the deterioration of the controller performance cannot be diagnosed and corrected timely, the malfunction would cause the damage at the expense of the company's operating margin. Without requiring the traditional complex physical model, a diagnosis system based on the controlled output variance is developed in order to assess the current controller performance, diagnose and remove the root causes resulting in performance deterioration. The resulting techniques are being applied to a variety of academic and industrial cases. (由於許多製程已運作數年,但操作問題仍長久未被診斷出問題。當控制器的效能每況愈下而未被發現並及時矯正時,這不僅會造成設備功能損害,更會侵蝕公司的營運利潤。我們發展出以根據控制輸出變異的診斷樹狀系統,無需傳統複雜的模式,就可以評估目前控制器的表現,且藉由診斷將可移除造成效能降低的根源。這些技術現正用於各種學術與工業的例子當中。)
|
|
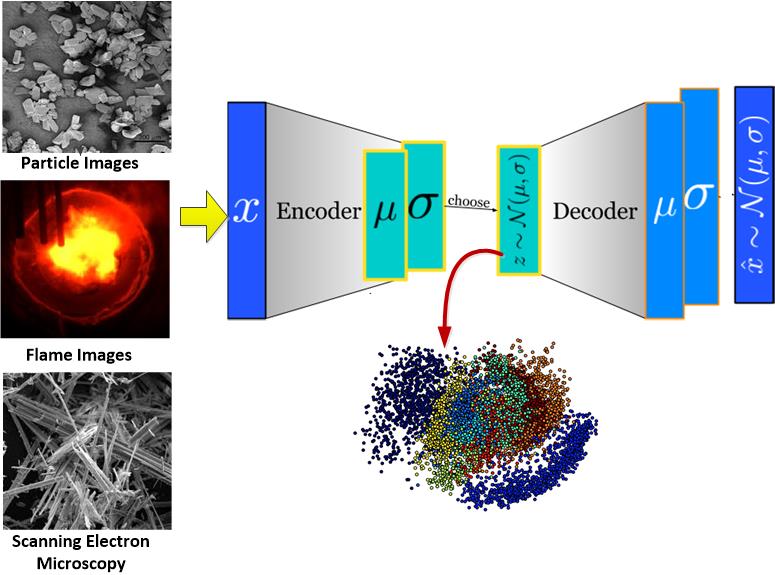
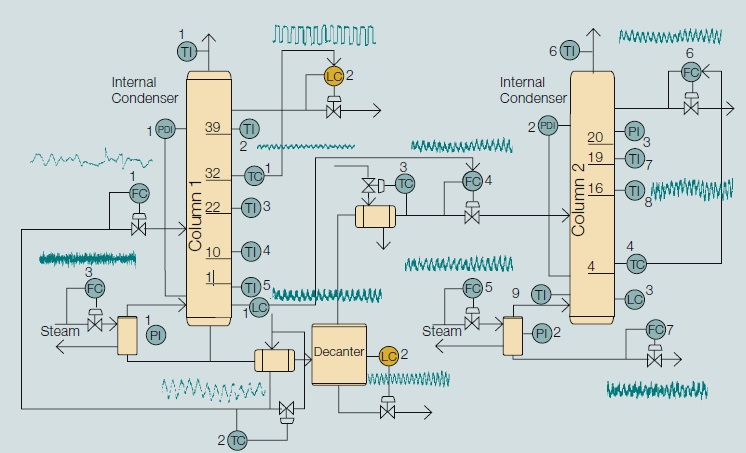
With the advance in optical sensing and image capture systems, process images offer new perspectives on process monitoring. Although the information from process images is enriched, how to convert the huge number of images into usable information is an enormous challenge. Recently, the deep learning has attracted extensive attention. What makes deep learning so attractive? It is because the use of a deeper (more hidden layers) neural network can extract more useful info from the data. With the capacity of extracting different levels of features for better classification and recognition, deep learning is considered as the most general and effective methodology for information extraction of massive data. The current techniques in deep learning yield dazzling levels of performance. It outsmarts the other machine learning techniques as well as the other neural networks. In this work, a deep learning algorithm is used to enhance data mining for a huge amount of plant data, like flame image-based process monitoring and UTDR data for membrane filtration FDD. (深度學習是一種機械學習的技術,但深度學習為何如此吸引人?其實它是利用一深度(具有多層的隱藏層)的類神經網路,可由數據中抽取出更有用的訊息。目前深度學習的技術已產生相當強的效能,並且比其他機械學習與類神經網路更有智慧。在此研究中,我們將利用深度學習的演算法,提升工業巨量數據的數據挖掘技術,如火焰影像的製程監控,以及UTRD數據於膜過濾的錯誤監控與診斷。)
 |
 |
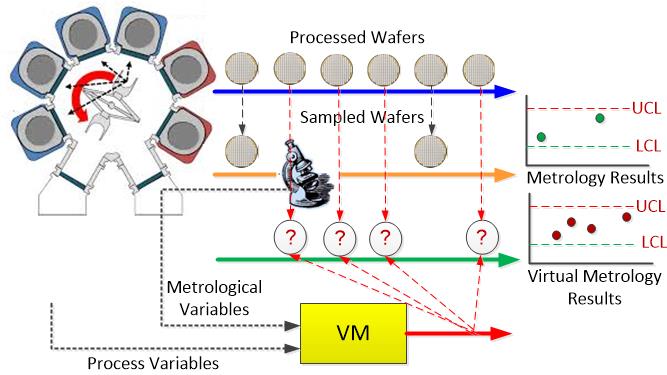
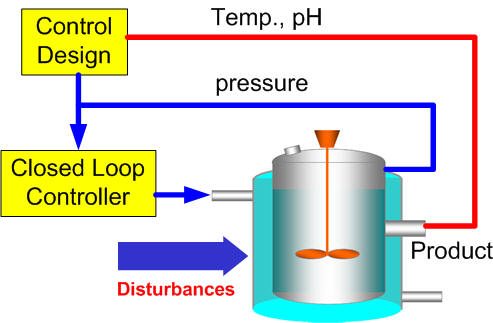
As the current market is highly competitive, product life cycles are becoming shorter and shorter. Time-to-market, quality and individualization are the main competitive factors at successful manufacturers. This especially rings true in the complex processes, such as pharmaceutical, biochemical, specialty chemical and semiconductor processes. Current research is developing several data-driven control strategies based on the multivariable statistical techniques and the iterative learning control. These strategies are shown to be superior to the traditional run-to-run methods. They are applied to the assessment of process design of the semiconductor processes, the membrane filtration and the simulated moving bed systems.(當前市場正承受極高度的競爭,產品的生命週期也越來越短。而即時將產品導入市場、優良品質,以及各別的差異化,是成就成功的製造商主要競爭的因素,這特別是在複雜的製程,如醫藥、生化、特用化學品、與半導體的工業最為常見。目前的研究正發展幾種以數據導向的控制策略,這些策略是運用多變數的統計技術與重覆學習的控制策略,我們已証實優於傳統的批次對批次的方法。目前這些策略正應用於半導體製程、薄膜過濾及模擬移動床系統的製程,以進行可行性評估。)
|
|
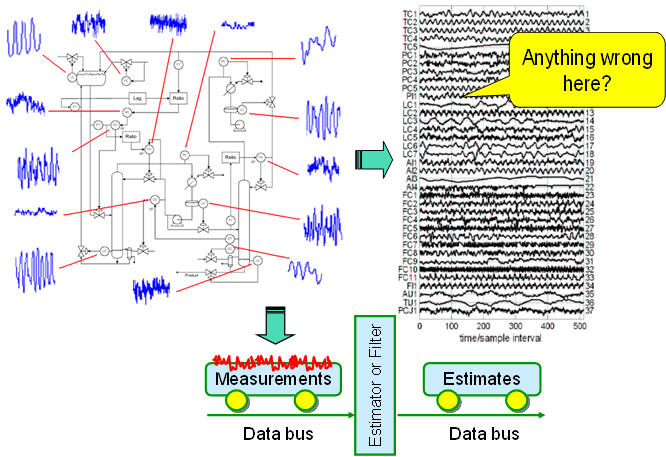
Measured data validation plays an important role in process operation analysis and enhancement since measured signals of process variables are often contaminated by measurement errors because of instrument imperfections. Under normal circumstances, process data are inaccurate since they are affected by random errors and possibly gross errors. Data reconciliation is the procedure of estimating true values of measured variables from collected measurements.
Specific Applications
|
|
|
|